

Understanding Batch Processing: A Beginner's Guide
S
Fullstack developer with intrest in genAi I Love building project which convert into product. I have been learning system design these days
Search for a command to run...
Fullstack developer with intrest in genAi I Love building project which convert into product. I have been learning system design these days
No comments yet. Be the first to comment.
In computer networks, this is one of the most asked and fundamental topics. Let me break it down with a simple example. Suppose you are sending a video on WhatsApp to your friend. The network you are using is the same network that many other people a...
Well, you have come a long way in your DevOps journey. When your application gets more requests than usual, the server running your application can't handle the load. Traditionally, there are two ways to scale up your server, as you just saw in the b...
Deciding Factor , Why you choose devops ? 💡 Feel free to skip this section it , it includes what are the factors and why you have choose to learn devops . if you are aware and curios to learn feel free to move to next heading As a student conside...

Well, everybody might be wondering who I am ? I am Suraj Vishwakarma from Bangalore, currently pursuing a B.Tech in Computer Science from Lovely Professional University. I have always been interested in playing with computers. I got my first PC when ...

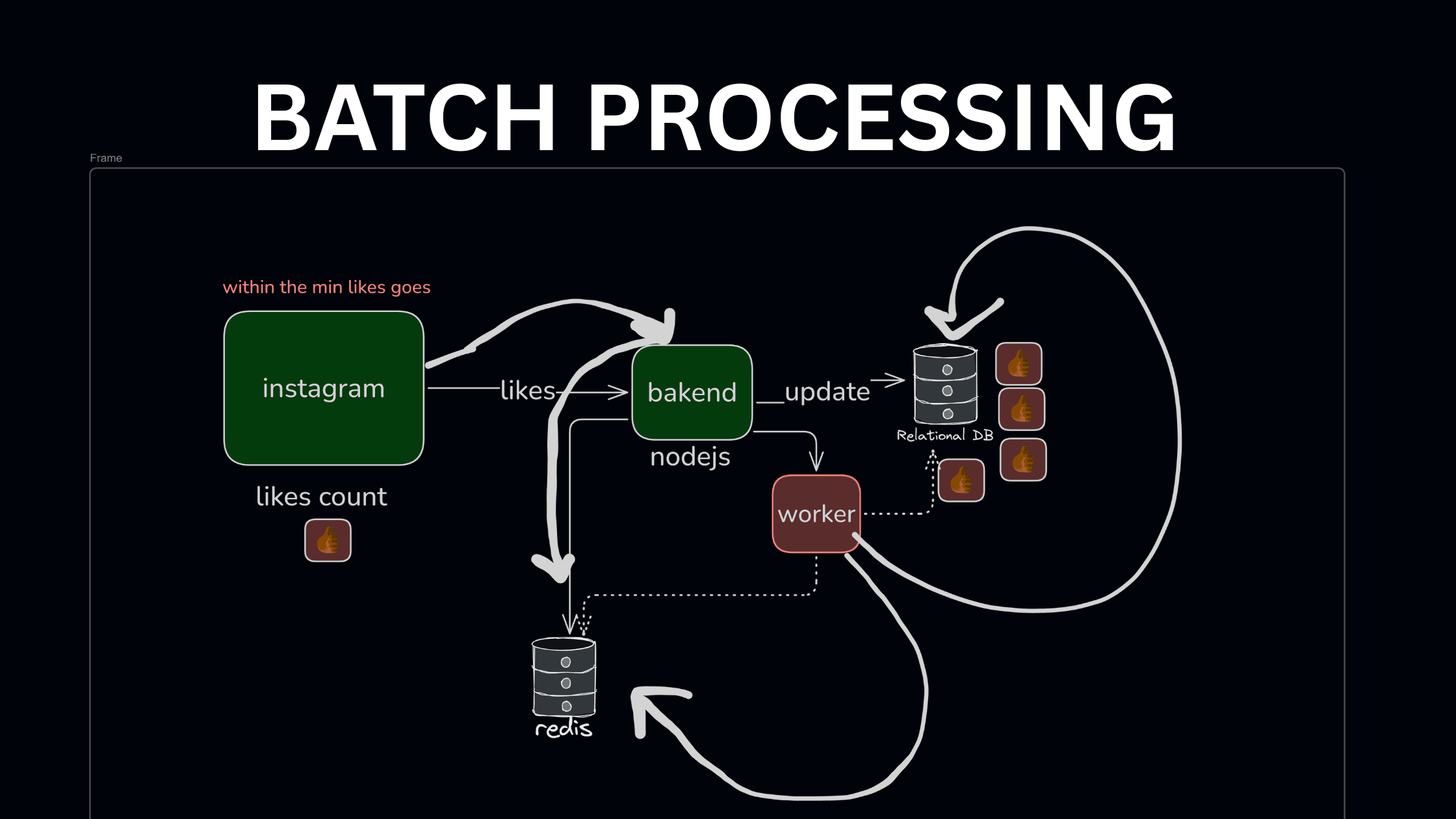
Imagine being a celebrity with a massive following. Every time you post, you receive an overwhelming number of likes. Now, picture getting 100,000 likes within minutes. Would Instagram update its database 100,000 times in one minute to reflect this?
When a celebrity posts a photo and receives 100,000 likes in minutes, a critical question arises:
Would Instagram really hit its database 100,000 times in one minute just to update a like counter?
The answer is simple: no — and it shouldn’t.
This is where batch processing becomes essential.
In this guide, we’ll explore:
The pitfalls of naïve database updates at scale
How large systems manage massive write traffic
A practical batch-processing architecture
Implementation using Redis and worker-based batching
This is not just theory; it’s how production systems operate.
A straightforward method to handle likes involves:
User clicks Like
Backend increments likes_count in the database
Immediate database write
If 100,000 users like a post within a minute, this results in:
100,000 database write operations
Heavy lock contention on the same row
Increased latency for all users
Risk of database throttling or outages
Relational databases are not designed for extremely high-frequency writes on the same record. If Instagram followed this approach, their database would struggle to cope.
Big systems adhere to a key principle:
User experience must be fast; database writes can be delayed.
A like doesn’t need to be immediately stored in permanent storage. A short delay is acceptable and invisible to users.
The strategy involves:
Quickly accepting likes
Storing them in a fast in-memory system
Persisting them to the database in batches
Batch processing involves:
Collecting multiple events over time
Processing them together as a group
Dramatically reducing system load
Instead of:
100,000 likes → 100,000 database writes
We achieve:
100,000 likes → 1 Redis counter → 1 batched database write
This results in a 100,000x improvement in write efficiency.
Here’s the high-level architecture:
User clicks Like
Backend updates Redis (fast, in-memory)
A background worker runs periodically
Worker reads accumulated likes from Redis
Worker updates the database in batches
Redis is ideal for this scenario because:
It’s in-memory, making it extremely fast
Supports atomic operations (INCR)
Can handle millions of operations per second
Temporary data storage is acceptable
A database ensures durability, while Redis provides speed.
When a user likes a post:
redis.incr(`post:likes:${postId}`)
Benefits include:
O(1) operation
No database lock
Immediate user response
At this stage:
The UI can display the updated count
The database remains untouched
A background worker runs every few seconds or minutes.
Fetch all like counters from Redis
Aggregate them
Write updates to the database
Reset Redis counters
Pseudo-flow:
for each postId in redisKeys:
likes = redis.get(postId)
UPDATE posts SET likes_count = likes_count + likes
redis.del(postId)
This reduces thousands of updates to one update per post per interval.
This is a design decision:
Every 5 seconds → more real-time, more database writes
Every 1 minute → fewer database writes, slight delay
Production systems adjust based on:
Traffic
Database capacity
Acceptable data freshness
Instagram doesn’t require millisecond-accurate likes, nor do most apps.
If Redis crashes, likes in memory may be lost.
Mitigations:
Enable Redis persistence (AOF/RDB)
Accept minor data loss for non-critical metrics
Likes are eventually consistent, not financial transactions.
If a worker crashes mid-batch:
Redis data remains intact
The next worker run continues processing
This ensures the system is fault-tolerant.
Workers must be:
Idempotent
Or carefully delete Redis keys only after successful database writes
This prevents double-counting likes.
This approach is used for:
Like counters
View counts
Follower counts
Analytics events
Notifications
Any system with high write frequency employs batching. Similar patterns are found in:
YouTube
Netflix analytics
Databases shouldn’t handle extremely high-frequency writes
Redis absorbs traffic spikes
Batch workers ensure system stability
Eventual consistency is acceptable for metrics
For any application that might go viral, batch processing is essential.
Next time you see a post jump from 10K to 100K likes instantly, remember:
Behind the scenes, no database is being overwhelmed. A smart batching system is efficiently managing the load.
For students preparing for backend interviews or system design rounds, this pattern is invaluable. Understand it, implement it, and discuss it with confidence.